

Deepgram
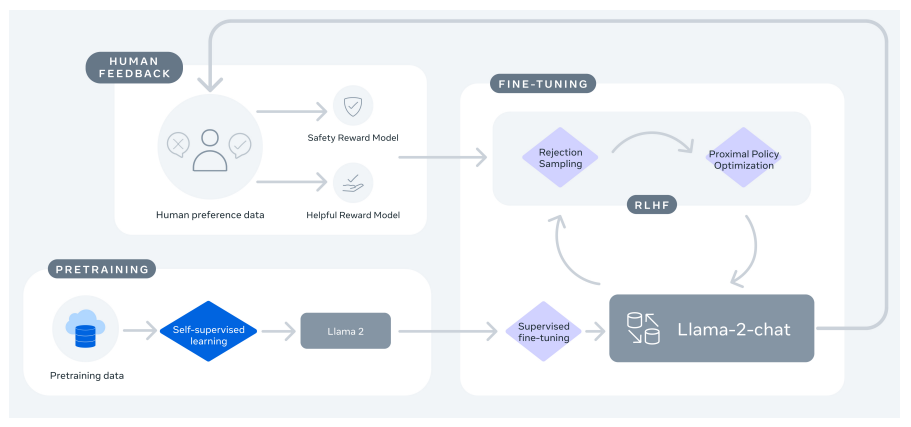
Llama-2 much like other AI models is built on a classic Transformer Architecture To make the 2000000000000 tokens and internal weights easier to handle Meta. Llama 2 is a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. Llama 2 is a family of pre-trained and fine-tuned large language models LLMs released by Meta AI in..
Agreement means the terms and conditions for use reproduction distribution and modification of the Llama. This is a bespoke commercial license that balances open access to the models with responsibility and protections in place to help address potential misuse Our license allows for broad commercial use as well as for. With each model download youll receive README user guide Responsible use guide. Llama 2 The next generation of our open source large language model available for free for research and commercial use Visit the Llama download form and accept our License In Llama 2 the size of the context in. Meta is committed to promoting safe and fair use of its tools and features including Llama 2 If you access or use Llama 2 you agree to this Acceptable Use Policy Policy..
Medium
Web Across a wide range of helpfulness and safety benchmarks the Llama 2-Chat models perform better. Web In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models. . Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion. Web Create your own chatbot with llama-2-13B on AWS Inferentia There is a notebook version of that tutorial here. Web Our fine-tuned LLMs called Llama-2-Chat are optimized for dialogue use cases. App Files Files Community 51 Discover amazing ML. Web Llama Chat uses reinforcement learning from human feedback to ensure safety and helpfulness..
Result All three currently available Llama 2 model sizes 7B 13B 70B are trained on 2 trillion tokens and have double the context length of Llama 1. Result LLaMA-2-7B-32K is an open-source long context language model developed by Together fine-tuned from Metas original Llama-2 7B model. Result To run LLaMA-7B effectively it is recommended to have a GPU with a minimum of 6GB VRAM A suitable GPU example for this model is the. Result Llama 2 is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 70 billion parameters. We extend LLaMA-2-7B to 32K long context using Metas recipe of interpolation and continued pre-training..



Komentar